Capítulo 2 Metodología y datos
2.1 Caso de estudio
El caso de estudio utilizado en este trabajo corresponde a un SCM que se inicio y alcanzo su madurez durante el 22 de noviembre de 2018 en el centro y norte de Argentina. Previo al desarrollo de este SCM, el centro y norte de Argentina se encontraba inmerso en una masa de aire cálido y húmedo con altos valores de energía potencial disponible convectiva (CAPE), como lo muestra ERA 5 (Hersbach et al., 2018) en la Figura 2.1a. En las Figuras 2.1a-c se puede apreciar una zona baroclínica en el campo de espesores 1000-500 hPa (contornos rojos discontinuos) y una vaguada en el campo de presión en superficie (contornos negros) que da cuenta de un frente frío que cruzó el centro de Argentina el 22 de noviembre de 2018. Este frente frío desencadenó el desarrollo de células convectivas aisladas que rápidamente crecieron hasta convertirse en un SCM excepcionalmente grande que puede observarse en las imágenes de temperatura de brillo del canal 13 de GOES-16 (Figura 2.1d,e). Durante ese día, varias estaciones de superficie observaron actividad eléctrica, fuertes ráfagas de viento y lluvias intensas. Al norte de la región, el entorno cálido y húmedo contribuyó al desarrollo de convección aislada que finalmente creció y se fusionó con el SCM (Figura 2.1f). El SCM recorrió aproximadamente 2500 km de sur a norte, disipándose sobre Paraguay y el sur de Brasil después de 42 horas desde el inicio de su desarrollo. Este caso de estudio es de particular interés por desarrollarse durante la campaña RELAMPAGO donde se generaron observaciones extraordinarias que son utilizadas en la verificación de los experimentos desarrollados.
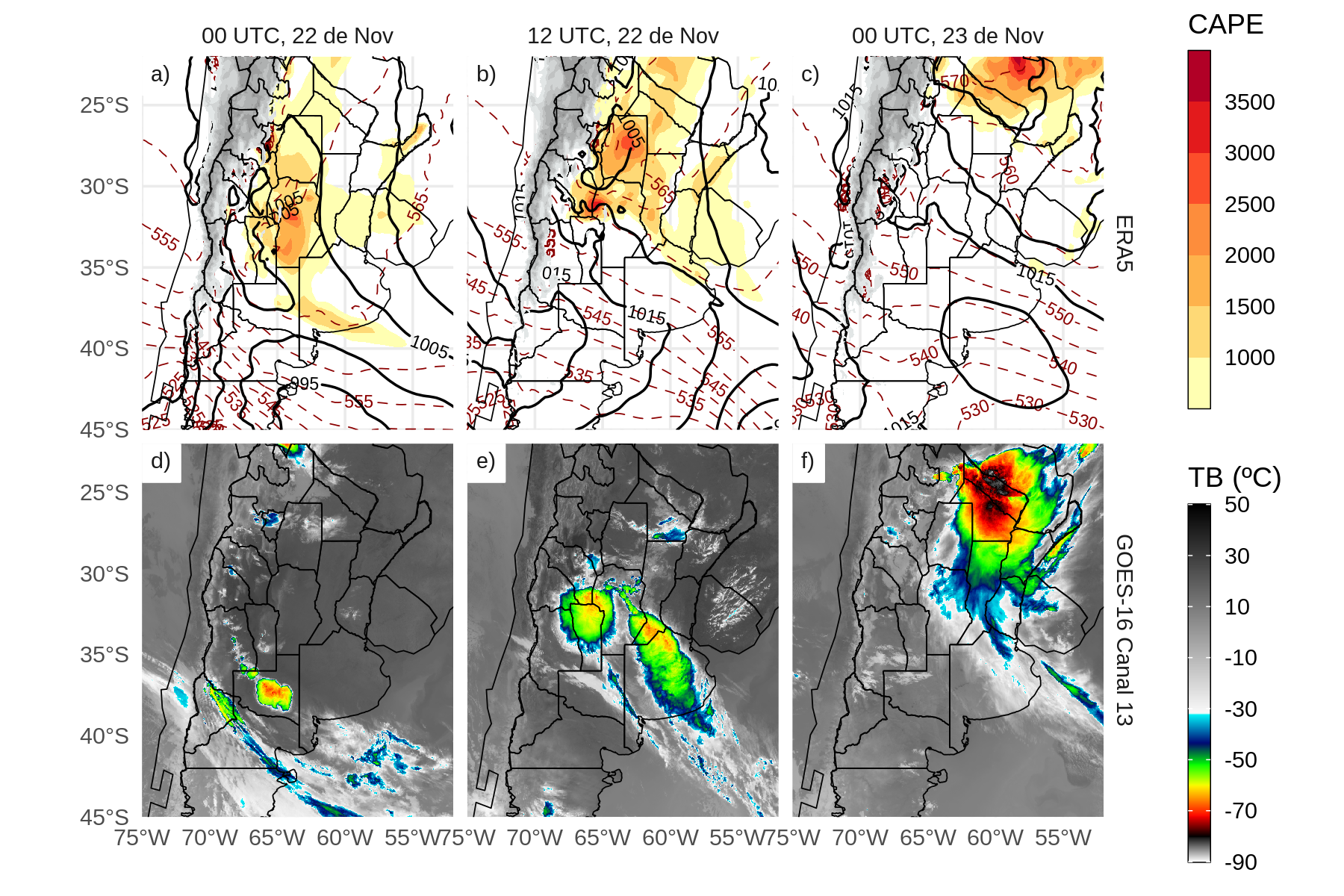
Figure 2.1: Presión a nivel del mar (hPa, contornos negros), espesor 1000-500 hPa (contornos rojos discontinuos) y energía potencial convectiva disponible (sombreada) según ERA5 y temperatura de brillo del canal 13 de GOES-16 para a,d) 00 y b,e) 12 UTC, 22 de Noviembre y c,f) 00 UTC, 23 de Noviembre.
2.2 Observaciones
Durante el periodo de estudio se realizaron diferentes experimentos para evaluar el impacto al asimilar diferentes fuentes de observaciones, entre los que se incluyen datos convencionales oficiales de superficie y altura, redes no oficiales de estaciones meteorológicas automáticas de superficie, vientos derivados de satélite, y radianzas en cielo despejado. También se utilizaron otras observaciones como radiosondeos para cuantificar la calidad de los análisis y pronósticos.
2.2.1 Conjuntos de observaciones asimiladas
2.2.1.1 Convencionales
Las observaciones convencionales (OMC) utilizadas forman parte del flujo de datos del Sistema Global de Asimilación de Datos (GDAS). Se asimilarán las observaciones convencionales incluidas en los archivos Binary Universal Form for Representation of Meteorological Data (PREPBUFR) generados por NCEP. Los archivos PREPBUFR incluyen observaciones de superficie procedentes de 117 estaciones meteorológicas de superficie (EMC), barcos, y observaciones de altura procedentes de 13 sitios de lanzamiento de radiosondeos y aviones dentro del área en estudio. Los triángulos naranjas de la Figura 2.2a indican la ubicación de las estaciones de superficie incluidas en este experimento. La frecuencia de estas observaciones varia entre 1 hora para las estaciones de superficie y 12/24 horas para los radiosondeos. Las observaciones del viento en superficie sobre los océanos (ASCATW) proceden de los dispersómetros y también se incluyen en los archivos PREPBUFR.
La tabla 2.1 enumera todos los tipos de observación (presión en superficie, temperatura, humedad específica y viento) disponibles para cada fuente de observación, junto con el error asociado para cada una definidos de acuerdo a la configuración por defecto del sistema de asimilación usado en este trabajo. En algunos casos, el error varía con la altura y depende de la plataforma específica (avión y viento derivado del satélite). En cuanto al control de calidad aplicado a las observaciones convencionales, el sistema de asimilación realiza una primera comparación entre la innovación (la diferencia entre la observación y la observación simulada por el modelo para el campo preliminar) y un umbral predefinido que depende del error de observación (también incluido en la Tabla 2.1).
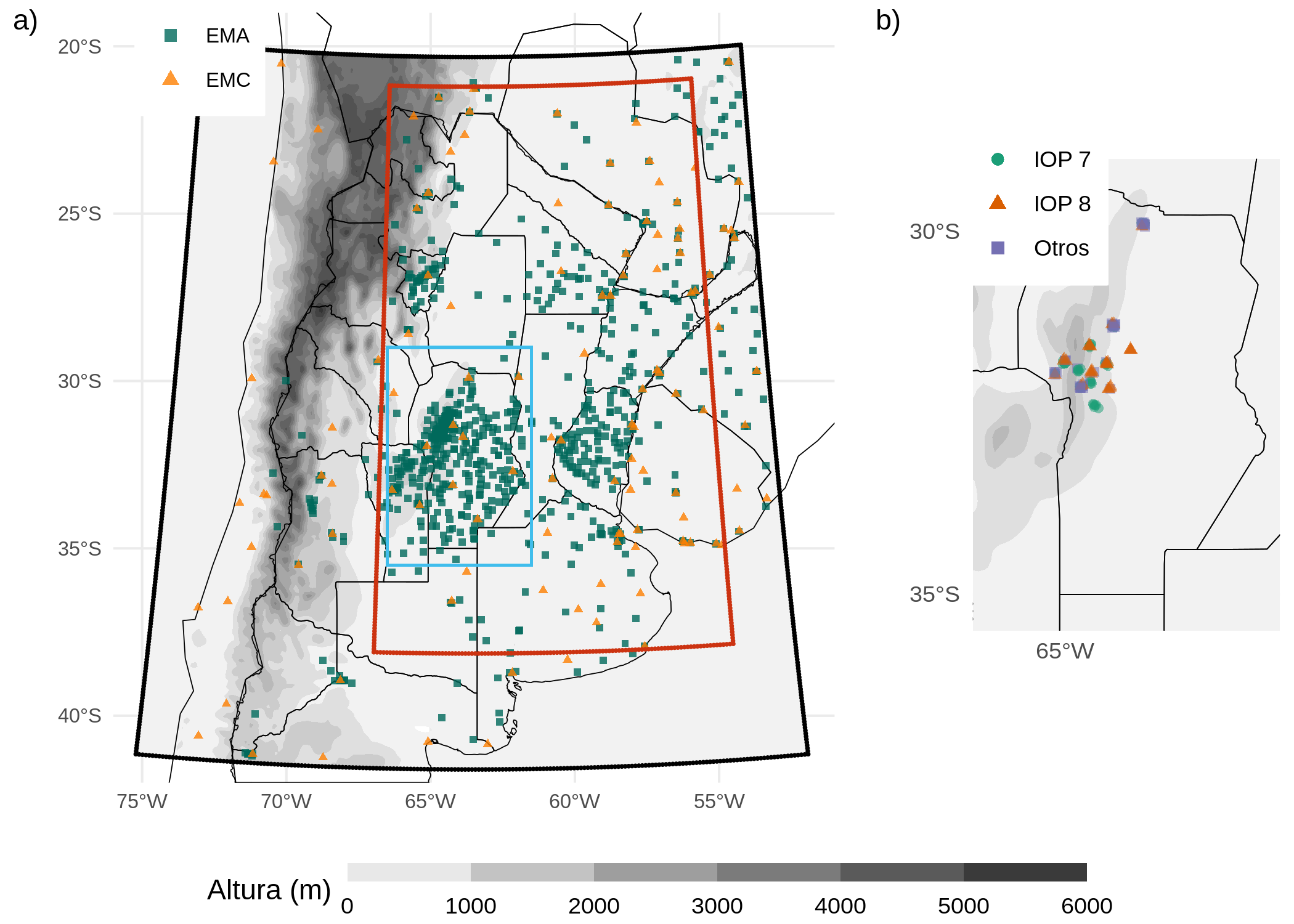
Figure 2.2: a) Dominio utilizado para las simulaciones (recuadro negro), dominio interior utilizado para la comparación entre experimentos (recuadro rojo), la región mostrada en b) (recuadro azul claro), y la ubicación de las Estaciones Meteorológicas Automáticas (EMA, cuadrados verdes) y las Estaciones Meteorológicas Convencionales (EMC, triángulos naranjas). b) Ubicación de los lanzamientos de radiosondeos durante RELAMPAGO. Los puntos verdes corresponden a los radiosondeos lanzados durante el IOP 7, los triángulos naranjas son radiosondeos lanzados durante el IOP 8, y los cuadrados morados son radiosondeos lanzados fuera de los periodos de medición intensiva. También se muestra la topografía en metros (sombreada).
2.2.1.2 Red de Estaciones Meteorológicas Automáticas
También se asimilaron observaciones de 866 Estaciones Meteorológicas Automáticas (EMA) que forman parte de 17 redes de superficie públicas y privadas en la región. El conjunto de datos utilizado en este estudio fue obtenido del repositorio de datos de RELAMPAGO (Garcia et al., 2019). Estas estaciones se indican como cuadrados verdes en la Figura 2.2a. Tienen mayor cobertura espacial que las EMC y una frecuencia de muestreo de 10 minutos en la mayoría de los casos. Todas las estaciones miden temperatura, pero sólo 395 estaciones proporcionan humedad, 422 la presión y 605 el viento. Los errores de observación utilizados para asimilar estas observaciones son los mismos que para las observaciones de EMC (véase la tabla 2.1).
2.2.1.3 Vientos estimados por satélite
Las observaciones de viento derivadas de los satélites también se incluyen en los archivos PREPBUFR disponibles cada 6 hs, y consisten en estimaciones de GOES-16 (utilizando los canales visible, infrarrojo y de vapor de agua) y METEOSAT 8 y 11 (utilizando los canales visible y de vapor de agua). Estos satélites son geoestacionarios y tienen una frecuencia de escaneo de 15 minutos durante el evento analizado, por lo que, ante la presencia de nubosidad para estimar el viento, generarán estimaciones que estarán disponibles en cada ciclo de asimilación (ver Capítulo 3, Figura 3.3). Las observaciones de viento derivadas de los satélites METEOSAT tienen una resolución de 3 km mientras que las de GOES-16 tienen una resolución de 10 km. Debido al dominio elegido y la cobertura de estos satélites, GOES-16 es la principal fuente de observaciones de vientos derivados de los satélites (99 % de las observaciones). Los errores de observación utilizados para asimilar estas observaciones siguen la configuración por defecto del GSI y se indican en la Tabla 2.1 bajo el nombre SATWND.
| Código | Plataforma | Variable | Error | Umbral de error |
|---|---|---|---|---|
| EMC EMA | Estaciones meteorológicas de superficie | Presión | 1-1.6 \(hPa^*\) | 3.6 \(hPa\) |
| Temperatura | 1.5 \(K\) | 7 \(K\) | ||
| Humedad específica | 20 % | 8 \(gkg^{-1}\) | ||
| Viento | 2.2 \(ms^{-1}\) | 6 \(ms^{-1}\) | ||
| ADPUPA | Radiosondeos | Presión | 1.1-1.2 \(hPa^{**}\) | 4 \(hPa\) |
| Temperatura | 0.8-1.5 \(K^*\) | 8 \(K\) | ||
| Humedad específica | 20 % | 8 \(gkg^{-1}\) | ||
| Viento | 1.4-3 \(ms^{-1}\)* | 8 \(ms^{-1}\) | ||
| AIRCFT | Aviones | Temperatura | 1.47-2.5 \(K^+\) | 7 \(K\) |
| Viento | 2.4-3.6 \(ms^{-1+}\) | 6.5-7.5 \(ms^{-1+}\) | ||
| ASCATW | Dispersómetros | Viento | 1.5 \(ms^{-1}\) | 5 \(ms^{-1}\) |
| SFCSHP | Barcos y boyas | Presión | 1.3 \(hPa\) | 4 \(hPa\) |
| Temperatura | 2.5 \(K\) | 7 \(K\) | ||
| Humedad específica | 20 % | 8 \(gkg^{-1}\) | ||
| Viento | 2.5 \(ms^{-1}\) | 5 \(ms^{-1}\) | ||
| SATWND | Viento derivado de satélites | Viento | 3.8-8 \(ms^{-1*+}\) | 1.3-2.5 \(ms^{-1+}\) |
| * El error de la observación varía con la altura. | ||||
| ** Observationes por encima de 600 hPa son rechazadas. | ||||
| + El error de la observación depende del tipo de reporte. |
2.2.1.4 Radianzas de satélite
2.2.1.4.1 Satélites polares
En este trabajo se utilizaron radianzas de satélites disponibles a través del flujo de datos del GDAS, que incluye observaciones en el espectro infrarrojo y microondas. Dado que el dominio regional que se utilizará en este trabajo se encuentra en latitudes medias y que la mayoría de los satélites de interés están en órbitas polares, cada sensor escanea la zona sólo dos veces al día con una cobertura espacial que depende de la franja de cobertura del satélite. Por esta razón, el número de observaciones de los satélites polares varía significativamente en cada ciclo de asimilación. En particular, los sensores multiespectrales proporcionaron entre 10.000 y 100.000 observaciones en el dominio de interés por cada escaneo cada 12 horas, contribuyendo al 88 % de la cantidad total de radianzas asimiladas (Tabla 2.2) en los experimentos descriptos en la Sección 3.1.1.
Los sensores microondas disponibles para ser asimilados en el periodo de interés son el Advanced Microwave Sounding Unit - A (AMSU-A) a bordo de las plataformas NOAA-15, NOAA-18 y METOP-A, y el Microwave Humidity Sounder (MHS) a bordo de las plataformas NOAA-19, METOP-A y METOP-B.
AMSU-A (Robel and Graumann, 2014) es un radiómetro de microondas que cuenta con 15 canales de observación diferentes entre 23.8 - 89 GHz y ha demostrado ser un importante sensor para el sondeo de la temperatura atmosférica (English et al., 2000). Cada canal detecta la radiación de microondas procedente de distintas capas de la atmósfera terrestre, cuya localización se describe mediante la función de peso, que corresponde a la derivada de la transmitancia con respecto a la altura. Estas funciones de peso son necesarias para definir la ubicación de las observaciones y por lo tanto en que espesor de la atmósfera generaran un impacto al momento de la asimilación. El AMSU-A es conocido como un “sensor de temperatura” ya que sus canales fueron seleccionados para detectar la radiación emitida por capas sucesivas de la atmósfera. La Figura 2.3a muestra las funciones de peso en cielo claro para aquellos canales del AMSU-A que tienen sensibilidad en la tropósfera. No se incluyen en la asimilación de observaciones los dos primeros canales ubicados en 23.8 y 31.4 GHz ya que estos son sensibles a la fase líquida de las nubes y a la emisividad de la superficie, aunque si aportan información para el control de calidad de las observaciones de otros canales.
Por ejemplo, la función de peso del canal 7 (54.94 GHz) muestra que la contribución máxima a la radiación de microondas detectada por el instrumento AMSU-A proviene de aproximadamente una altura de 10 km por encima de la superficie. Como indica la Tabla 2.2 solo entre 2 y 4 canales del sensor AMSU-A se asimilaron en este trabajo. Entre los canales asimilados se encuentran los canales 5 a 8 (53.596, 54.4, 54.94 y 55.5 GHz respectivamente).
| Sensor | Plataforma | Canales asimilados | Porcentaje sobre el total |
|---|---|---|---|
| AIRS | AQUA | 52 | 31.63 % |
| AMSUA | NOAA15 | 2 | 3.31 % |
| NOAA18 | 2 | 4.45 % | |
| METOP-A | 2 | 2.08 % | |
| IASI | METOP-A | 66 | 52.72 % |
| METOP-B | 68 | 3.47 % | |
| MHS | NOAA19 | 2 | 0.68 % |
| METOP-A | 3 | 0.8 % | |
| METOP-B | 3 | 0.85 % |
De manera similar, el sensor microondas MHS es conocido por ser un “sensor de humedad”. Este sensor tiene dos canales sensibles a la superficie y la presencia de nubes (canales 1 y 2: 89 y 157 GHz), y tres canales mayoritariamente sensibles al vapor de agua (canales 3, 4 y 5: 183.3 \(\pm\) 1.0, 183.3 \(\pm\) 3.0 y 190 GHz). Como indican las funciones de peso (Figura 2.3b), todos los canales del MHS se encuentran por debajo del tope del modelo, sin embargo, como se puede ver en la Tabla 2.2, entre 2 y 3 canales se asimilan en los experimentos llevados a cabo en esta tesis. El canal 5 no es utilizado en algunas situaciones ya que se ve afectado por la presencia de nubes y las observaciones son rechazadas durante el control de calidad. Los canales 1 y 2 no son asimilados debido a que la información que aportan proviene principalmente de la superficie.
En cuanto a los sensores multiespectrales, se asimilaron dos: el Atmospheric Infrared Sounder (AIRS) y el Infrared Atmospheric Sounding Interferometer (IASI) ubicados en distintas plataformas (ver Tabla 2.2). IASI mide la radiación emitida por la Tierra en 8461 canales que cubren el intervalo espectral del infrarrojo térmico entre 645 y 2760 \(cm^{-1}\) (3.62 - 15.5 \(\mu m\)). De manera similar, AIRS tiene canales en 3 rangos del espectro electromagnético: 645 y 1136 \(cm^{-1}\), 1265 y 1629 \(cm^{-1}\), y 2169 y 2674 \(cm^{-1}\) donde la transmisividad de la atmósfera varía rápidamente con la frecuencia y por lo tanto cada canal aporta información en distintos niveles de la atmósfera. Asimilar la totalidad de estos canales no es recomendable ya que tanto las observaciones como sus errores se encuentran muy correlacionados entre si, es por ello que numerosos estudios que se han enfocado en definir un conjunto de canales adecuado en el contexto de los pronósticos numéricos globales para su asimilación (por ejemplo, Collard, 2007; Rabier et al., 2002). Realizar un estudio de sensibilidad de los canales para la región de interés esta fuera del alcance de los objetivos de este trabajo, por lo que se decidió utilizar la configuración regional del sistema GSI en la cual se asimilan entre 52 y 68 canales distintos (ver Tabla 2.2). Las diferencias en la cantidad de canales y/o cantidad de observaciones asimiladas para un mismo sensor a bordo de distintas plataformas puede deberse a la presencia de errores sistemáticos o a fallas conocidas en los canales de sensores específicos que son rechazados durante la asimilación.
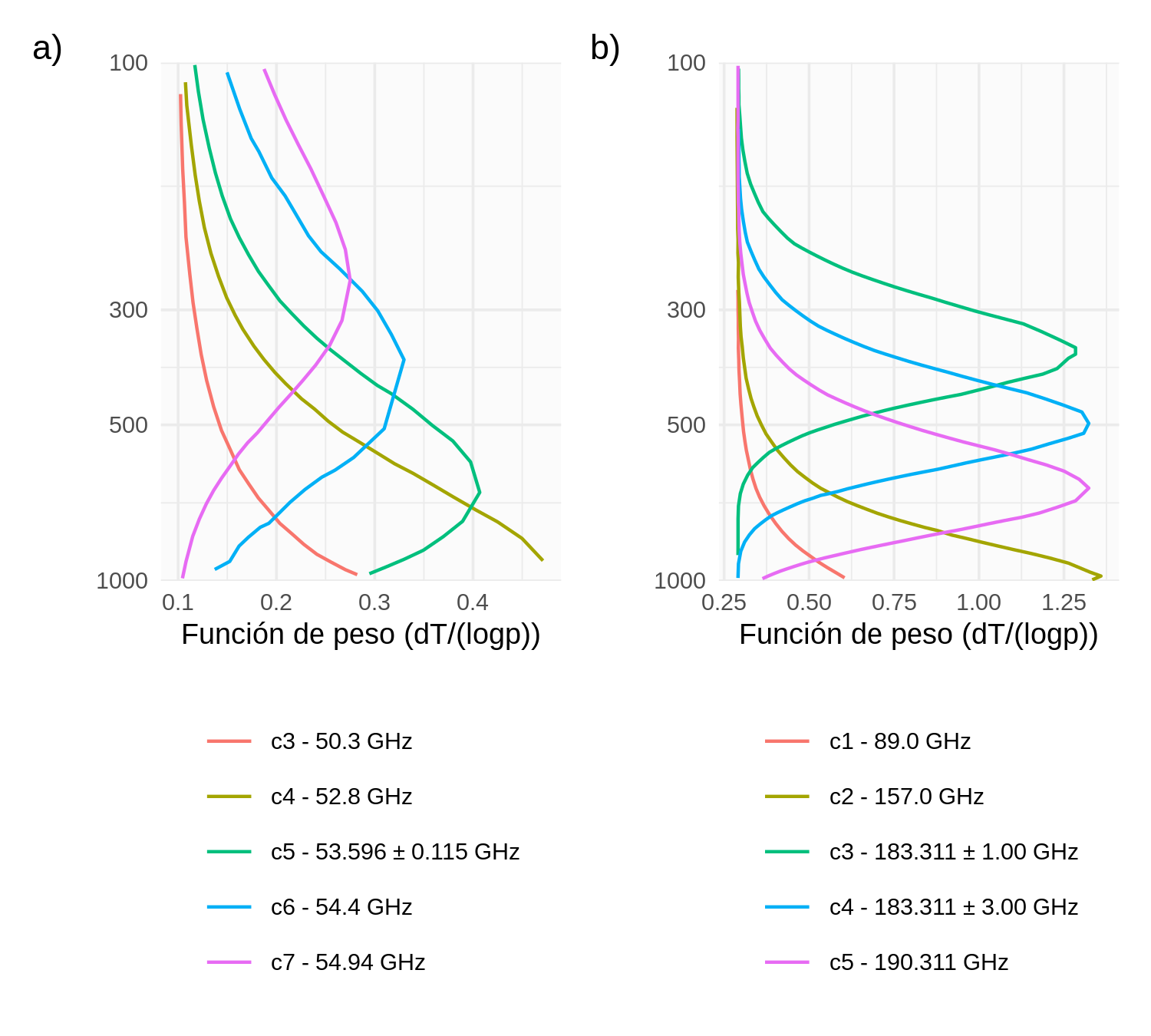
Figure 2.3: Funciones de peso calculada sobre cielos despejados asumiendo una atmósfera estándar para distintos sensores y canales, a) AMSU-A, canal 3 - 50.3 GHz, canal 4 - 52.8 GHz, canal 5 - 53.596 \(\pm\) 0.115 GHz, canal 6 - 54.4 GHz, canal 7 - 54.94 GHz; y b) MHS, canal 1 - 89.0 GHz, canal 2 - 157.0 GHz, canal 3 - 183.311 \(\pm\) 1.00 GHz, canal 4 - 183.311 \(\pm\) 3.00 GHz, canal 5 - 190.311 GHz.
2.2.1.4.2 GOES-16
En el trabajo también se evaluó la utilización del satélite geoestacionario GOES-16. En particular se utilizaron observaciones del sensor Advanced Baseline Imager (ABI) que tienen una frecuencia temporal de 15 minutos y una resolución espacial de 2 kilómetros aportando más observaciones que el conjunto de satélites polares utilizados.
Teniendo en cuenta los objetivos propuestos, se asimilaron los canales sensibles al vapor de agua en distintos niveles, información que puede ser clave a la hora de pronosticar el desarrollo de convección húmeda profunda:
- Canal 8 (6.2 \(\mu m\)): vapor de agua en niveles altos
- Canal 9 (6.9 \(\mu m\)): vapor de agua en niveles medios
- Canal 10 (7.3 \(\mu m\)): vapor de agua en niveles bajos
La Figura 2.4 muestra las funciones de peso calculadas para una atmósfera estándar en latitudes medias para cada uno de estos canales. Si bien hay un solapamiento en las funciones de peso, para una atmósfera estándar, el canal 8 es más sensible al vapor de agua alrededor de los 350 hPa, el canal 9 alrededor de 450 hPa y el canal 10 alrededor de los 600 hPa aproximadamente. Además, la contribución de estos canales por encima de 50 hPa es mínima por lo que su asimilación en aplicación regionales donde el tope de la atmósfera suele ser bajo, no presenta grandes desafíos. En la Sección 5.2.1 se analizará que combinación de canales da mejores resultados en el contexto de este caso de estudio.
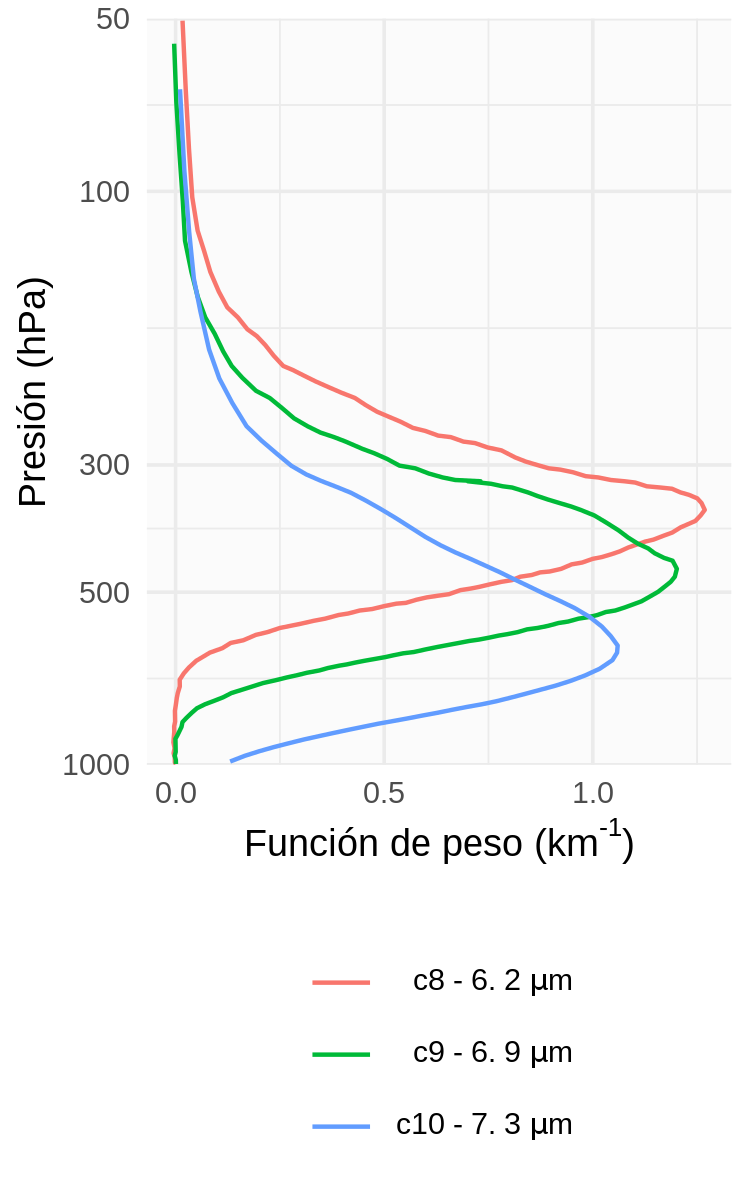
Figure 2.4: Funciones de peso calculada sobre cielo claro para ABI, canal 8 - 6.2 \(\mu m\), canal 9 - 6.9 \(\mu m\), canal 10 - 7.3 \(\mu m\).
2.2.2 Conjuntos de observaciones para verificación
Para evaluar el desempeño del sistema de asimilación de datos presentado en esta tesis, utilizamos los siguientes conjuntos de observaciones:
Datos horarios en niveles de presión de ERA5 (Hersbach et al., 2018): Las variables de interés (temperatura del aire, humedad y viento) fueron interpoladas desde la retícula del reanálisis que tiene una resolución de 0.25\(^{\circ}\) a la retícula del modelo para compararlas con el análisis de cada experimento.
Multi-Network Composite Highest Resolution Radiosonde Data (Earth Observing Laboratory, 2020): radiosondeos en alta resolución lanzados desde varias ubicaciones durante el periodo de la campaña de campo RELAMPAGO en conjunto con las radiosondeos operativos del SMN. Sólo se utilizaron para la validación los sondeos que no ingresaron en el sistema de asimilación y que corresponden a los sitios de observación de la campaña. El periodo del experimento abarca las misiones Intensive Observation Period (IOP) 7 (21/11/2018) y 8 (22/11/2018), durante las cuales se lanzaron 74 radiosondeos en una pequeña zona cercana al centro del dominio experimental (Figura 2.2b). Estas observaciones son de particular importancia ya que si bien corresponden a una región acotada del dominio, aportan información de alta resolución vertical y temporal en comparación con los radiosondeos operacionales que se lanzan una o dos veces al día. Esto además permite observar la capa límite a lo largo de un periodo de tiempo extendido donde normalmente no se cuenta con observaciones convencionales.
IMERG Final Run (Huffman et al., 2018): estimación de la precipitación a partir de datos de la constelación de satélites GPM (por su nombre en inglés Global Precipitation Measurement) con una resolución espacial de 0,01\(^{\circ}\) y una resolución temporal de 30 minutos para validar la habilidad de los pronósticos de 1 hora para representar la precipitación sobre el dominio. La estimación de la precipitación se realiza combinando observaciones de sensores de microondas activos y pasivos que se complementa con estimaciones provenientes de sensores infrarrojos a bordo de satélites polares. Los datos de IMERG son ampliamente utilizados en la región y han sido evaluados previamente con buenos resultados (Hobouchian et al., 2018).
Datos del Sistema Nacional de Radares Meteorológicos (SINARAME): Se utilizaron observaciones de radar para realizar una evaluación cualitativa y visual de la ubicación e intensidad de la actividad convectiva. Los datos provienen de 9 radares ubicados en el dominio y son provistos por la red de radares Doppler de doble polarización en banda C (de Elía et al., 2017) con una frecuencia temporal de 10 minutos. Para este trabajo se utilizó únicamente la máxima reflectividad de la columna (COLMAX) más cercana al momento de análisis que incluye el control de calidad de los datos (Arruti et al., 2021).
Observaciones de las redes de estaciones meteorológicas automáticas: Las observaciones de EMA descriptas en la Sección 2.2.1.2 fueron utilizadas en la verificación de pronósticos inicializados a partir de los análisis generados. Las observaciones utilizadas para validar los pronósticos son posteriores a las utilizadas para generar las condiciones iniciales de dichos pronósticos.
2.3 La asimilación de datos
La asimilación de datos combina de manera optima un pronóstico numérico o campo preliminar en un periodo de tiempo \(t\) con las observaciones disponibles para ese mismo tiempo, generando un análisis (Carrassi et al., 2018). Esta combinación optima toma en cuenta el error asociado a la predicción numérica (que incluye los errores debido a la imperfección de las condiciones iniciales y aquellos asociados a la imperfección del modelo) y el error de las observaciones (que resulta de los errores instrumentales y los errores de representatividad). Por esta razón el análisis es considerado desde un punto de vista estadístico y bajo ciertas hipótesis, como la mejor aproximación disponible del estado real de la atmósfera.
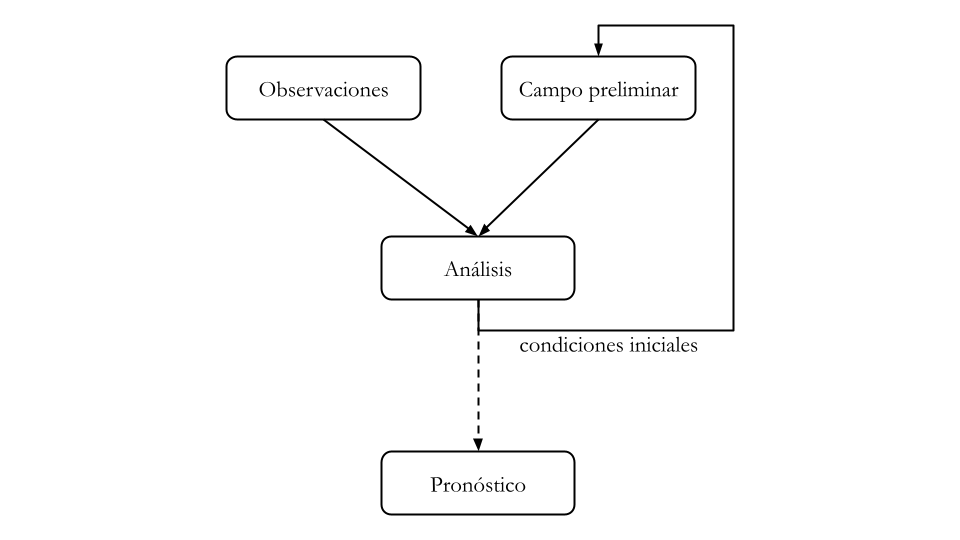
Figure 2.5: Esquema de un ciclo de asimilación típico.
Un ciclo de asimilación de datos típico se muestra en la Figura 2.5. En un periodo de tiempo dado se comparan las observaciones disponibles con el campo preliminar para ese mismo periodo, generando así el análisis que se utilizará como condición inicial para un futuro pronóstico o campo preliminar. En el caso de modelos globales, típicamente cada ciclo de asimilación cada 6 horas utiliza el campo preliminar previo, es decir el pronóstico a 6 horas inicializado a partir del análisis anterior y las observaciones disponibles en la ventana de asimilación que corresponde a las 6 horas previas o en un periodo similar centrado en la hora del análisis. Muchos sistemas de asimilación utilizan, además, se utilizan estrategias 4D donde las observaciones dentro de la ventana de asimilación se comparan con el campo preliminar más cercano a esas observaciones.
En este sentido tanto el modelo como las observaciones cumplen un rol fundamental en la asimilación. Por un lado las observaciones permiten incorporar información continua para corregir los pronósticos. Por el otro, el modelo permite transportar información de regiones donde existe mucha información disponible (por ejemplo, los continentes) a regiones donde las observaciones son escasas (zonas oceánicas) manteniendo los balances físicos que rigen los procesos atmosféricos.
Existen distintas técnicas de asimilación de datos, cada una con sus ventajas y desventajas que fueron descriptas por Dillon (2017) en su tesis doctoral. En este trabajo, al igual que en trabajos previos en Argentina, se utilizará la técnica Local Ensemble Transform Kalman filter (LETKF, Hunt et al., 2007) que forma parte de un conjunto de técnicas basadas en Filtros de Kalman por ensambles (Evensen, 2009). Los Filtros de Kalman utilizan el ensamble, un conjunto de pronósticos ligeramente diferentes que se resuelven simultáneamente, para representar posibles estados futuros de la atmósfera cuya ocurrencia se considera equiprobable dado la incertidumbre presente en las condiciones iniciales. El ensamble además provee información dependiente de la dinámica durante la ventana de asimilación y permite estimar el error del modelo a lo largo del tiempo.
A fin de simplificar la siguiente discusión, asumimos que la comparación entre el modelo y las observaciones se realiza en un tiempo \(t\) y no en un periodo de tiempo. En el contexto de los Filtros de Kalman, el análisis o \(x_a\) estará representado por un vector columna de dimensión \(n_x\) x \(1\), donde \(n_x\) es la dimensión del estado simulado por el modelo. A su vez, \(x_a\) será el estado más probable de la atmósfera teniendo en cuenta las \(n_o\) observaciones \(y_o\) (vector de dimensión \(n_o\) x \(1\)) disponibles en un tiempo \(t\). Para asimilar las observaciones el primer paso es comparar el valor de la variable observada con el valor de la variable simulada por el modelo. En casos simple, por ejemplo para la temperatura o humedad en superficie, esto solo requiere la interpolación de la variable del modelo a la ubicación de las observaciones. En otros casos, por ejemplo cuando se trabaja con observaciones de satélite o radar, será necesario transformar las variables del modelo (ej. temperatura y humedad) para obtener las variables observadas (ej. temperatura de brillo). En la siguiente ecuación \(H\) es el operador de las observaciones que se encarga de las interpolaciones y transformaciones necesarias sobre el campo preliminar \(x_f\), representado como un vector de dimensión \(n_x\). Teniendo en cuenta las transformaciones que pueda realizar \(H\), este operador podría ser no lineal.
\[\begin{equation} x_a = x_f + K[y_o - H(x_b )] \tag{2.1} \end{equation}\]
La diferencia entre las observaciones \(y_o\) y el campo preliminar se denomina innovación. El análisis \(x_a\) se obtiene aplicando las innovaciones al campo preliminar pesadas por una matriz \(K\) o Ganancia de Kalman. Esta matriz de dimensión \(n_x\) x \(n_o\) que incluye información sobre los errores del pronóstico y de las observaciones como se observa en la ecuación (2.2),
\[\begin{equation} K = PH^T (HPH^T + R^{-1})^{-1} \tag{2.2} \end{equation}\]
donde \(P\) es la matriz de covarianza de los errores del pronóstico. \(R\) es la matriz de covarianza de los errores de las observaciones que describe la magnitud del error de las observaciones en la diagonal y la correlación entre estos errores en los elementos fuera de la diagonal. Sin embargo, se asume que los errores de las observaciones son independientes y por lo tanto la matriz \(R\) es una matriz diagonal. La implementación de los los métodos de asimilación de datos suelen ser computacionalmente muy costosos, en parte debido a la estimación de la matriz \(P\). Los métodos de Filtro de Kalman por Ensambles tienen la ventaja de estimar la matriz \(P\) a partir del ensamble y actualizarla en cada ciclo de asimilación para incluir los errores dependientes de la dinámica del sistema siguiendo la ecuación:
\[\begin{equation} P \approx \frac{1}{m-1} \sum_{k=1}^{m}(x_{f}^{k}-\overline{x}_f)(x_{f}^{k}-\overline{x}_f)^T \tag{2.3} \end{equation}\]
donde \(x_{f}^{k}\) es el pronóstico del miembro k-ésimo del ensamble. Esta estimación será buena si el ensamble logra capturar los posibles estados futuros o en otras palabras si la dispersión es suficiente para estimar la incertidumbre de los pronósticos y capturar los cambios a lo largo de los ciclos de asimilación. El ensamble debe además tener un tamaño suficiente para representar las direcciones de máximo crecimiento de los errores que se asocian principalmente a la cantidad de modos inestables presentes en el sistema (Bousquet et al., 2008). Si esto ocurre la estimación de \(P\) será buena.
El método LETKF es una técnica eficiente ya que resuelve la ecuación (2.1) en un espacio de dimensión reducida definido por los miembros del ensamble. Por lo tanto la matriz \(K\) no se resuelve explicitamente, eliminando la necesidad de computar la inversa de matrices de gran tamaño. Cómo en el resto de los métodos que usan filtro de Kalman, se localiza o restringe el área de influencia de las observaciones a un determinado radio de localización reduciendo el costo computacional necesario. La localización tiene además otra ventajas. Por un lado, y desde el punto de vista dinámico las inestabilidades en la atmósfera son de naturaleza local y por lo tanto el tamaño del ensamble necesario para representar estas inestabilidades será menor que si miramos el problema globalmente (Patil et al., 2001). Por otro lado la localización reduce el impacto de las covarianzas espurias entre entre variables del estado y observaciones que están alejadas entre si y cuyos errores son independientes reduciendo el ruido estadístico en la estimación del análisis. Además, este método calcula el análisis para cada punto de retícula individualmente, incorporando todas las observaciones que puedan tener influencia en ese punto al mismo tiempo permitiendo paralelizar los cálculos. De esta manera este método es hasta un orden de magnitud más rápido comparado con otros métodos desarrollados previamente (Whitaker et al., 2008).
2.3.1 El sistema de asimilación GSI
GSI por su nombre en inglés Gridpoint Statistical Interpolation, es un sistema de asimilación de datos de última generación, desarrollado inicialmente por el Environmental Modeling Center del NCEP. Se diseñó como un sistema 3DVAR tradicional aplicado en el espacio de puntos de retícula de los modelos para facilitar la implementación de covarianzas anisotrópicas no homogéneas (Wu et al., 2002; Purser et al., 2003a, 2003b). Está diseñado para funcionar en varias plataformas computacionales, crear análisis para diferentes modelos numéricos de pronóstico, y seguir siendo lo suficientemente flexible como para poder manejar futuros desarrollos científicos, como el uso de nuevos tipos de observación, una mejor selección de datos y nuevas variables de estado (Kleist et al., 2009).
Este sistema 3DVAR sustituyó al sistema de análisis operativo regional de punto de retícula del NCEP por el Sistema de Predicción de Mesoescala de América del Norte (NAM) en 2006 y al sistema de análisis global Spectral Statistical Interpolation (SSI) usado para generar las condiciones iniciales del Global Forecast System (GFS) en 2007 (Kleist et al., 2009). En los últimos años, GSI ha evolucionado para incluir varias técnicas de asimilación de datos para múltiples aplicaciones operativas, incluyendo 2DVAR (por ejemplo, el sistema Real-Time Mesoscale Analysis (RTMA); Pondeca et al., 2011), la técnica híbrida EnVar (por ejemplo los sistemas de asimilación de datos para el GFS, el Rapid Refresh system (RAP), el NAM, el HWRF, etc.), y 4DVAR (por ejemplo, el sistema de asimilación de datos para el Sistema Goddard de Observación de la Tierra, versión 5 (GEOS-5) de la NASA; Zhu and Gelaro, 2008). GSI también incluye un enfoque híbrido 4D-EnVar que actualmente se utiliza para la generación del GFS.
Además del desarrollo de técnicas híbridas, GSI permite el uso de métodos de asimilación por ensambles. Para lograr esto, utiliza el mismo operador de las observaciones que los métodos variacionales para comparar el campo preliminar con las observaciones. De esta manera los exhaustivos controles de calidad desarrollados para los métodos variacionales también son aplicados en la asimilación por ensambles. El código EnKF fue desarrollado por el Earth System Research Lab (ESRL) de la National Oceanic and Atmospheric Administration (NOAA) en colaboración con la comunidad científica. Contiene dos algoritmos distintos para calcular el incremento del analisis, el serial Ensemble Square Root Filter (EnSRF, Whitaker and Hamill, 2002) y el LETKF (Hunt et al., 2007) aportado por Yoichiro Ota de la Agencia Meteorológica Japonesa (JMA).
Para reducir el impacto de covarianzas espurias en el incremento que se aplica al análisis, los sistemas por ensamble aplican una localización a la matriz de covarianza de los errores de las observaciones \(R\) tanto en la dirección horizontal como vertical. GSI usa un polinomio de orden 5 para reducir el impacto de cada observación de manera gradual hasta llegar a una distancia límite a partir de la cual el impacto es cero. La escala de localización vertical se define en términos del logaritmo de la presión y la escala horizontal usualmente se define en kilómetros. Estos parámetros son importantes a la hora de obtener un buen análisis y dependen de factores como el tamaño del ensamble y la resolución del modelo. La configuración utilizada para los experimentos de esta tesis se describe en la Sección 2.4.
A su vez utiliza el Community Radiative Transfer Model (CRTM, Liu et al., 2008) como operador de las observaciones de radianzas que calcula la temperatura de brillo simulada por el modelo para poder compararlo con las observaciones de sensores satelitales. GSI, además implementa un algoritmo de corrección de bias de las observaciones de radianzas de satélites. La estimación hecha por el campo preliminar obtenida con el CRMT se compara con las observaciones de radianza para obtener la innovación. Esta innovación a su vez se utiliza para actualizar los coeficientes que permiten estimar el bias de las observaciones que posteriormente se aplica para obtener una innovación corregida. Este proceso puede repetirse varias veces hasta que la innovación y los coeficientes de corrección de bias converjan. Este algoritmo se describe en mayor detalle en la Sección 2.3.1.2.
2.3.1.1 El modelo de transferencia radiativa CRTM
El CRTM es un modelo de transferencia radiativa rápido que fue desarrollado conjuntamente por el NOAA Center for Satellite Applications and Research y el Joint Center for Satellite Data Assimilation (JCSDA). Es un modelo utilizado ampliamente por la comunidad de sensoramiento remoto ya que es de código abierto y se encuentra disponible para su uso públicamente. Además, se utiliza para la calibración de instrumentos satelitales (Weng et al., 2013; Iacovazzi et al., 2020; Crews et al., 2021), y a su vez para generar retrievals a partir de observaciones satélites (Boukabara et al., 2011; Hu et al., 2019; Hu and Han, 2021). De especial importancia para este trabajo, es su uso como operador de observaciones en la asimilación de radianzas satelitales (Tong et al., 2020; Barton et al., 2021).
El CRTM es capaz de simular radianzas de microondas, infrarrojas y visibles, en condiciones de cielos despejados y nubosos, utilizando perfiles atmosféricos de presión, temperatura, humedad y otras especies como el ozono. Recientemente Cutraro et al. (2021) evaluaron su despeño en la región con buenos resultados en la simulación de observaciones de GOES-16.
El CRTM es un modelo de transferencia radiativa orientado a sensores, es decir que contiene parameterizaciones y tablas de coeficientes precalculadas específicamente para los sensores operativos. Incluye módulos que calculan la radiación térmica a partir de la absorción gaseosa, la absorción y dispersión de la radiación por aerosoles y nubes, y la emisión y reflexión de la radiación por la superficie terrestre. La entrada al CRTM incluye variables de estado atmosférico, por ejemplo, temperatura, vapor de agua, presión y concentración de ozono en capas definidas por el usuario, y variables y parámetros de estado de la superficie, incluyendo la emisividad, la temperatura de la superficie y el viento.
El CRTM permite simular observaciones satelitales de radianzas a partir del estado de la atmósfera. Esto es necesario para la asimilación de radianzas pero también es utilizado para verificar la precisión y los errores de estas observaciones.
El cálculo de las observaciones simuladas tiene un costo computacional muy alto ya que requiere transponer un matriz de grandes dimensiones y la minimización de una función de costo. Esta matriz \(K^{*}\) se construye a partir de las derivadas parciales de las radianzas con respecto a parámetros geofísicos. CRTM permite hacer estos cálculos de manera rápida para que pueda usarse en contextos operacionales.
Para obtener resultados rápidos, CRTM aplica ciertas simplificaciones y aproximaciones a la hora de resolver la ecuación de transferencia radiativa. En primer lugar asume que la atmósfera terrestre está formada por capas plano-paralelas y homogéneas en equilibrio termodinámico y donde los efectos tridimensionales y de polarización pueden ser ignorados.
En contextos de cielos despejados, además se asume que no existe dispersión y solo se considera la absorción de los gases en la atmósfera. En cielos nubosos, la dispersión generada por las nubes si es incluida. En este último caso, la ecuación de transferencia radiativa no se puede resolver analíticamente y se recurre a modelos numéricos.
2.3.1.2 Asimilación de radianzas en GSI
El preprocesamiento y control de calidad de los datos es un paso esencial en la asimilación de radianzas y depende de cada sensor y canal. Esto incluye principalmente un thinning espacial, la corrección del bias, y en particular en este estudio la detección de observaciones de cielos nubosos. Primero se aplicó un thinning espacial. Durante el proceso de thinning las observaciones que se van a asimilar se eligen en función de su distancia a los puntos de la retícula del modelo, la calidad de la observación (basada en la información disponible sobre la calidad de los datos) y el número de canales disponibles (para el mismo píxel y sensor). El algoritmo de thinning determina la calidad de los datos en este punto según la información disponible sobre los canales que son conocidos por tener errores, la superficie por debajo de cada píxel (prefiere observaciones sobre el mar a las de la tierra o nieve) y predictores sobre la calidad de las observaciones (Hu et al., 2018). El objetivo al aplicar thinning es evitar incorporar información de procesos de escalas menores a las que puede representar el modelo y reducir la correlación en los errores de las observaciones que vienen de un mismo sensor.
Luego del thinning, se aplica la corrección de bias. La metodología de corrección de bias implementada en GSI tiene una componente dependiente de características termodinámicas del aire y otro dependiente del ángulo de escaneo (Zhu et al., 2014) y se calcula como una polinomio lineal de N predictores \(p_i(x)\), con coeficientes asociados \(\beta_i\). Por lo tanto, la temperatura de brillo corregida por bias (\(BT_{cb}\)) puede obtenerse como
\[\begin{equation} \mathrm{\mathit{BT_{cb}} =\mathit{ BT} + \sum_{i = 0}^{N} \beta_i p_i (x)} \tag{2.4} \end{equation}\]
GSI tiene un término de corrección de bias constante (\(p_0 = 1\)) mientras que los términos restantes y sus predictores son el contenido de agua líquida de las nubes (CLW), la tasa de cambio de temperatura con la presión, el cuadrado de la tasa de cambio de temperatura con la presión y la sensibilidad de la emisividad de la superficie para tener en cuenta la diferencia entre la tierra y el mar. El bias dependiente del ángulo de escaneo se modela como un polinomio de 4\(^\circ\) orden (Zhu et al., 2014).
En el sistema GSI, los coeficientes \(\beta_i\) se entrenan utilizando un método de estimación variacional que genera los \(\beta_i\) que proporciona el mejor ajuste entre la simulación y las observaciones.
La metodología de detección de pixeles nubosos depende de la longitud de onda de las observaciones. Para las radianzas de microondas, las observaciones potencialmente contaminadas por nubes se detectan utilizando los índices de dispersión y del Liquid Water Path (LWP) calculados a partir de diferencias entre distintos canales de cada sensor (Zhu et al., 2016; Weston et al., 2019). Para los canales infrarrojos, las observaciones contaminadas por nubes se detectan utilizando el perfil de transmitancia calculado por el modelo CRTM. Además, GSI comprueba la diferencia entre las observaciones y la temperatura de brillo simulada para detectar los píxeles nublados. Un caso particular son las observaciones de ABI ya que se utiliza la mascara de nubes que se genera como producto de nivel 2 y que está disponible con la misma resolución que las observaciones. Esta máscara de nubes se genera combinando información de 8 canales del sensor ABI desde el punto de vista espacial y temporal.
Por otro lado, el control de calidad de GSI filtra aquellas observaciones de canales cercanos al rango visible sobre superficies de agua con un ángulo cenital mayor a 60\(^{\circ}\) para rechazar aquellas observaciones que pudieran estar contaminadas por reflexión. Para las observaciones en el infrarrojos y microondas también realiza una chequeo de la emisividad para detectar observaciones contaminadas por efecto de la superficie. Finalmente se aplica un gross check, es decir, se compara la diferencia entre la observación y la observación simulada por el modelo y un umbral predefinido que depende del error de observación para rechazar observaciones erróneas.
La ubicación vertical de cada observación de radianza se estimó como el nivel del modelo en el que se maximizaba su función de peso calculada por el CRTM. La función de peso de cada canal corresponde al cambio en la transmitancia con la altura y su máximo describe la capa de la atmósfera desde donde la radiación captada por el canal fue emitida. Los sensores multiespectrales tienen una buena cobertura vertical y son capaces de captar desde la baja troposfera hasta la baja estratosfera. Los canales elegidos para la asimilación y sus errores asociados se definieron teniendo en cuenta la configuración que GSI utiliza para generar los análisis y pronósticos de GFS, el tope del modelo elegido en este trabajo (50 hPa) y la posible influencia de la superficie (Tabla 2.2).
2.4 Configuración del sistema de asimilación
Las simulaciones numéricas que conforman los experimentos que se discuten en este trabajo se realizan utilizando la versión 3.9.1 de modelo WRF (Skamarock et al., 2008). Se utilizó una resolución horizontal de 10 km y 37 niveles en la vertical con el tope del modelo en 50 hPa. Las condiciones iniciales y de contorno surgen del análisis del Global Forecast System con una resolución horizontal de 0,25\(^{\circ}\) y frecuencia temporal de 6 horas (GFS, National Centers for Environmental Prediction, National Weather Service, NOAA, U.S. Department of Commerce, 2015). El dominio de 150 x 200 puntos de retícula cubre la zona indicada en la Figura 2.2 para capturar el desarrollo del SCM durante el periodo simulado.
Los análisis se generaron utilizando la implementación LETKF (V1.3, Hunt et al., 2007) que forma parte del sistema de asimilación Gridpoint Statistical Interpolation (GSI V3.8; Shao et al., 2016). Se utilizó un enfoque de actualización rápida con análisis horarios y una ventana de asimilación centrada, lo que significa que se asimilaron todas las observaciones dentro de \(\pm\) 30 minutos del tiempo de análisis. Además, las observaciones se asimilaron usando un enfoque 4D, es decir, comparándolas con el campo preliminar más cercano disponible con una frecuencia de 10 minutos. Para las observaciones de satélite, se utilizó el CRTM como operador de observaciones para calcular las temperaturas de brillo simuladas por el modelo.
Se generó un ensamble de 60 miembros, cuya media al principio del ciclo de asimilación de datos se inicializa utilizando el análisis determístico del GFS al que se le suman perturbaciones aleatorias para generar el ensamble inicial. Las perturbaciones se generaron como diferencias escaladas entre dos estados atmosféricos aleatorios obtenidos a partir de los datos del Climate Forecast System Reanalysis (CFSR) con una resolución horizontal de 0,5\(^{\circ}\) que tiene una evolución temporal suave (Necker et al., 2020; Maldonado et al., 2021). De este modo, preservamos el equilibrio hidrostatico y casi geostrófico de las escalas mayores. Este método ayuda a evitar una subestimación del spread del ensamble (Ouaraini et al., 2015). Las perturbaciones también se aplicaron en los bordes laterales para mantener niveles adecuados de spread dentro del dominio del ensamble.
Además de las perturbaciones aleatorias en los bordes laterales, se utilizó un esquema de multifísicas para representar mejor el aporte de los errores de modelo a la incertidumbre del pronóstico dentro del sistema de asimilación de datos. Utilizamos 9 configuraciones diferentes que consisten en la combinación de 3 esquemas de convección húmeda (Kain-Fritsch, Kain, 2004; Grell-Freitas, Grell and Freitas, 2013; y Betts-Miller-Janjic, Janjić, 1994) y 3 esquemas de capa límite planetaria (esquema de la Universidad de Yonsei, Hong, Noh, et al., 2006; Esquema Mellor-Yamada-Janjic, Janjić, 1994; y Mellor-Yamada Nakanishi Niino, Nakanishi and Niino, 2009). La distribución de estas parametrizaciones entre los 60 miembros del ensamble se muestra en la Tabla 2.3. Todos los miembros del ensamble utilizan el modelo de superficie terrestre (Noah-MP, Chen and Dudhia, 2001) y parametrizaciones de microfísica (esquema de un solo momento de 6 clases del WRF, Hong, Kim, et al., 2006) y de procesos radiativos (esquema de onda corta y onda larga del RRTMG, Iacono et al., 2008).
| Cumulus | MYJ | MYNN2 | YSU |
|---|---|---|---|
| BMJ | 5, 14, 23, 32, 41, 50, 59 | 8, 17, 26, 35, 44, 53 | 2, 11, 20, 29, 38, 47, 56 |
| GF | 6, 15, 24, 33, 42, 51, 60 | 9, 18, 27, 36, 45, 54 | 3, 12, 21, 30, 39, 48, 57 |
| KF | 4, 13, 22, 31, 40, 49, 58 | 7, 16, 25, 34, 43, 52 | 1, 10, 19, 28, 37, 46, 55 |
Para reducir el efecto de las correlaciones espurias en la estimación de las covarianzas de los errores de los pronósticos, utilizamos un radio de localización horizontal de 180 km y un radio de localización vertical de 0,4 (en coordenadas del logaritmo de la presión) como en Dillon et al. (2021) para todos los tipos de observaciones. Se aplicó con un parámetro de inflación \(\alpha=0,9\) que incrementa el spread del análisis para mitigar el impacto de los errores de muestreo y para considerar los errores del modelo que no se tienen en cuenta en el enfoque multifísica del ensamble (Whitaker and Hamill, 2012).
Los errores de las observaciones utilizados fueron definidos de acuerdo a las tablas de errores disponibles como parte del sistema GSI. Para las observaciones de radianzas polares se aplicó un thinning con una retícula de 60 km siguiendo Singh et al. (2016), Jones et al. (2013) y Lin et al. (2017) ya que utilizan configuraciones de modelo similares a la usada en este trabajo. Para las observaciones de GOES-16 se realizaron pruebas de sensibilidad para determinar la resolución de thinning más apropiada para este tipo de observaciones que se describen en la Sección 5.2.2.
Los coeficientes de corrección de bias para las observaciones de satélites polares se inicializaron a las 18 UTC del 18 de noviembre de 2018 a partir los coeficientes generados para la misma hora por el sistema GFS. El sistema de asimilación se configuró para utilizar una varianza de error de los coeficientes constante de 0,01 para evitar grandes ajustes en los coeficientes estimados en cada momento. Por razones que se describen en la Sección 5.1.1 se decidió no aplicar corrección de bias a las observaciones de GOES-16.
La Figura 2.6 muestra el proceso de asimilación de datos de manera resumida. En primer lugar se procesan las observaciones en formato bufr y se genera el campo prelimilar utilizando el modelo WRF. El sistema de asimilación se encarga, de la comparación entre las observaciones y el campo preliminar. En los casos necesarios, por ejemplo durante la asimilación de radianzas, intervienen operadores de las observaciones complejos como el CRTM. En este paso, además, las observaciones pasan por el control de calidad correspondiente. Finalmente, el sistema de asimilación aplica la innovación al campo preliminar para generar el análisis que se usará como condición inicial para futuros pronósticos o subsiguientes ciclos de asimilación.
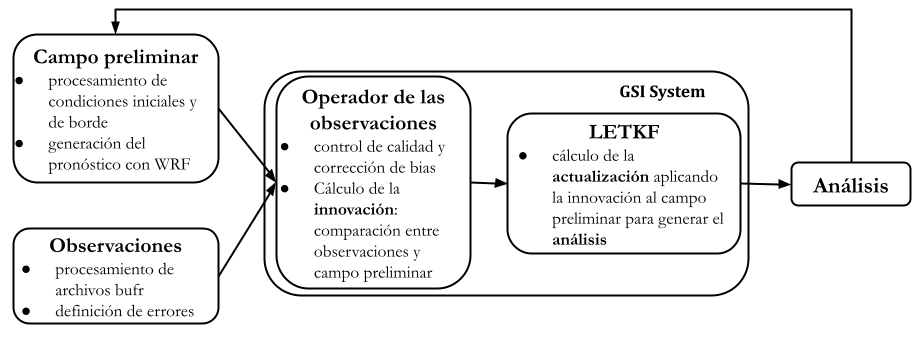
Figure 2.6: Diagrama del proceso de asimilación de datos.
2.5 Métodos de verificación
Se seleccionaron un conjunto de métricas para evaluar diferentes aspectos del análisis obtenido para cada experimento y los pronósticos inicializados a partir de ellos. Estas métricas incluyen una validación de cómo se cuantifica la incertidumbre en el campo preliminar y en el análisis, y cómo los diferentes experimentos se ajustan a un conjunto independiente de observaciones que no se asimilan.
Para evaluar la consistencia de la estimación de la incertidumbre en el campo preliminar y en el análisis utilizamos la Reduced Centered Random Variable o RCRV (Candille et al., 2007) que se define como:
\[\begin{equation} \mathit{RCRV} = \frac{m - x_o}{\sqrt{\sigma_o^2 + \sigma^2}} \tag{2.5} \end{equation}\]
donde \(x_o\) es la observación asimilada y la desviación estándar de su error \(\sigma_o\), \(m\) la media del ensamble del análisis en el espacio de las observaciones, y \(\sigma\) la desviación estándar del ensamble. La media de \(RCRV\) calculada sobre todas las realizaciones representa el sesgo de la media del conjunto con respecto a las observaciones normalizado por la desviación estándar estimada de la distancia entre dicha media y las observaciones:
\[\begin{equation} \mathit{mean RCRV} = E[RCRV] \tag{2.6} \end{equation}\]
La desviación estándar de la \(RCRV\) o \(sd RCRV\) mide la concordancia de la dispersión del ensamble y el error de observación con respecto a la distancia entre la media del ensamble y las observaciones, y por lo tanto, la sobre o subdispersión sistemática del ensamble:
\[\begin{equation} \mathit{sd RCRV} = \sqrt{\frac{1}{N -1}\sum_{i=1}^{N}(RCRV_i - \mathit{mean RCRV})^2} \tag{2.7} \end{equation}\]
donde \(N\) es la cantidad de observaciones utilizadas. Suponiendo que el error de observación fue estimado con precisión, un \(sd RCRV > 1\) indica que el ensamble es subdispersivo (es decir, la distancia entre las observaciones y los pronósticos es mayor de lo esperado), y un \(sd RCRV < 1\) indica que el conjunto es sobredispersivo (es decir, la distancia entre las observaciones y los pronósticos es menor de lo esperado). Un sistema consistente no tendrá sesgo (\(media RCRV = 0\)) y tendrá una desviación estándar igual a 1 (\(sd RCRV = 1\)).
Para analizar el ajuste del campo preliminar y el análisis a un conjunto de observaciones independientes se calculó la raíz del error cuadrático medio (RMSE) y el BIAS:
\[\begin{equation} \mathit{RMSE} = \sqrt{\frac{1}{N}\sum_{i = 1}^{N} (H(x_i) - y_{oi})^{2}} \tag{2.8} \end{equation}\]
\[\begin{equation} \mathit{BIAS} = \frac{1}{N}\sum_{i = 1}^{N} (X_i - y_{oi}) \tag{2.9} \end{equation}\]
donde \(H(x)\) representa el modelo interpolado al espacio de la observaciones, \(y_{o}\) las observaciones independientes, y N es el tamaño de la muestra.
Para aquellas observaciones disponibles en punto de grilla tales cómo la precipitación las estimaciones de precipitación de IMERG y la temperatura de brillo de GOES-16, calculamos el Fractions Skill Score (FSS, Roberts, 2008) para diferentes radios de influencia y umbrales de precipitación o temperatura de brillo con el objetivo de hacer una verificación espacial:
\[\begin{equation} \mathit{FSS} = 1-\frac{\sum_{i=1}^{N} ({P_x}_i-{P_o}_i)^{2}}{\sum_{i=1}^{N} ({P_x}_i)^{2}+\sum_{i=1}^{N} ({P_o}_i)^{2}} \tag{2.10} \end{equation}\]
donde \(P_{oi}\) es la proporción de puntos de retícula en el subdominio \(i-ésimo\), definido por el radio de influencia, donde la precipitación acumulada observada es mayor que un umbral especificado. Siguiendo a Roberts et al. (2020), \(P_{xi}\) se calcula sobre el ensamble completo y cuantifica la probabilidad de que la precipitación sea mayor al mismo umbral en cada punto de retícula, que luego es promediando sobre el subdominio \(i-ésimo\).
Esta métrica, a diferencia de otras como el RMSE que se calcula punto a punto, permite permite comparar el pronóstico con observaciones en distintas escalas espaciales. Esto es particularmente importante para variables como la precipitación o la temperatura de brillo que muchas veces es representada correctamente por el modelo en forma y magnitud pero en posiciones ligeramente distintas a lo observado.
Para los pronósticos por ensambles se calculó la probabilidad de precipitación por encima de determinados umbrales en cada punto de retícula como la proporción de miembros del ensamble que pronosticaron precipitación por encima de cada umbral. Además se generaron gráficos de confiabilidad (Wilks, 2011) con intervalos de probabilidades pronosticadas de 10% para analizar la calibración de los pronósticos inicializados a partir de los análisis de cada experimento.
Finalmente se calculó el índice de Brier (Brier, 1950) para evaluar el error cuadrático medio de las probabilidades de precipitación calculadas de acuerdo a la siguiente ecuación:
\[\begin{equation} \mathit{BS} = \frac{1}{N}\sum_{i=1}^{N} ({P_i}-{O_i})^{2} \tag{2.11} \end{equation}\]
donde \(P_i\) es la probabilidad pronosticada de la ocurrencia de un evento en el punto \(i-ésimo\) y \(O_i\) será 1 si se observó efectivamente la ocurrencia del evento y 0 si no.
2.6 Recursos computacionales
Todos los experimentos corrieron en la supercomputadora Cheyenne del National Center for Atmospheric Research (NCAR) (Computational and Information Systems Laboratory, 2019) que cuenta con 4032 nodos con 36 núcleos cada uno y 313 Tb de memoria de trabajo. El sistema de asimilación GSI y el modelo numérico WRF están programados en su totalidad en Fortran 90. Fue necesario incluir y modificar rutinas escritas en este lenguaje para ampliar las funcionalidades del sistema de asimilación, necesarias para algunos experimentos.
El postprocesamiento y análisis se realizó usando los recursos computacionales del Centro de Investigaciones del Mar y la Atmósfera. El análisis de datos se generó utilizando el lenguaje de programación R (R Core Team, 2020), utilizando los paquetes data.table (Dowle and Srinivasan, 2020) para trabajar con grandes volúmenes de datos y metR (Campitelli, 2020) para la lectura de archivos NetCDF y la visualización de datos grillados, entre otros. Todos los gráficos se han realizado con ggplot2 (Wickham, 2009) y la versión final de la tesis se generó con knitr, rmarkdown (Xie, 2015; Allaire et al., 2019) y thesisdown (Ismay and Solomon, 2022).
2.6.1 Disponibilidad de los datos
Debido a que cada experimento de asimilación, que incluye la media y miembros del análisis, media del campo preliminar, archivos diagnósticos y con información de las observaciones durante 66 ciclos de asimilación, requiere aproximadamente 1 Tb de memoria en disco, no es posible almacenar estos datos de manera abierta. Sin embargo los datos que surgen del postprocesamiento para generar los resultados de la tesis se encuentran disponibles en Zenodo (doi:10.5281/zenodo.7968629, versión 0.9).